Why AI Will Go Big By Thinking Small



Figuring out what comes next among the lightning-fast changes in generative AI is like playing Whac-A-Mole at 100x speed.
But a quick search on Hugging Face offers some clues. This repository of AI models includes some 180,000 (and growing quickly) from the likes of Google, Meta, and Intel, as well as many smaller players. To call it a hive of activity is an understatement: Some models tally downloads in the 10s of millions.
What are people doing with all these open-source AI models? Tinkering. Experimenting. Creating. Laying the groundwork for what will come next. And the implications are nothing short of transformative.
Role Model
We’re in the midst of a paradigm shift with generative AI. GPT-4, of course, put the stake in the ground: It’s a master model — a master brain, really — that set the world on fire by publicly exposing some of generative AI’s power and potential.
But the many models on Hugging Face and GitHub show that people are taking that master brain in a million different directions. They upload their experiments, which are then downloaded and modified, sometimes combined with other models, then reuploaded, only to be further tinkered with.
Some of these models act like GPT-4 or DALL-E, but work their magic in different ways to solve complicated AI tasks.
Take Microsoft’s Jarvis — a system controlled by a large language model (LLM) designed to connect with smaller models that act as collaborators. The goal: To solve ever-more complicated AI tasks, which Jarvis does in four stages:
- Task planning. Fulfilling a user request begins with understanding its intention. To do that, Jarvis enlists ChatGPT to turn the request into tasks that other models can execute.
- Model selection. Jarvis then turns to Hugging Face, where ChatGPT looks through descriptions for the most appropriate models.
- Task execution. Jarvis executes the tasks through the selected models and feeds results to ChatGPT.
- Response generation. Jarvis uses ChatGPT to integrate all of the model predictions and generate a complete response.
How powerful is this collaboration? Jarvis can solve the following complex instruction: “Please generate an image where a girl is reading a book, and her pose is the same as the boy in the image example.jpg. Then please describe the new image in your voice.”
You can see the result in this diagram:

(This project is based on the paper, "HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace." Read more about it.)
Models and processes like this give us a window into AI’s future: a few generic master models and many (many!) smaller, more specialized models, working in tandem with a master brain like GPT-4 to handle specific functions.
But this is only part of the story. After all, it wouldn’t be AI without a dash of magic.
Local Is the New Global
Sometimes, of course, great things come out of failed experiments. Meta’s powerful language model, LLaMa, was released on February 23 as an open-source package available only to researchers, who had to apply to use it.
Just a week later, it was leaked on 4Chan. But — debate about open vs. closed testing aside — it was clear that LLaMa comes with some serious power. According to Meta, LLaMa-13B outperforms GPT-3 on most benchmarks, all on a single GPU.
And in just a short time, researchers at Stanford were able to fine-tune LLaMa on a large set of dialogs. According to the researchers, they turned just 175 self-instruct seed tasks into 52k instruction-following examples and got it to behave like GPT-3.5.
It’s important to highlight that the way they did this marks yet another small breakthrough in the world of AI models. Handcrafting 52k dialogs is normally a very difficult and costly process, but the researchers from Stanford did it using ChatGPT, and the total cost for generating the training set was only $500!! Fine-tuning the relatively small LLaMa model was fast, cheap, and didn’t require a supercomputer.
So much progress, so fast!
This project, called Alpaca, turned out to have some deficiencies (like “hallucination”) and had to be taken down, but the learnings were astonishing. First, the researchers got Alpaca up and running for just a few hundred dollars. Even more amazingly, they reportedly ran it on simple, lower-power machines, like Raspberry Pi computers and a Pixel 6 smartphone — locally. No Internet required.
Here’s Alpaca running locally on my laptop, writing a poem about me:
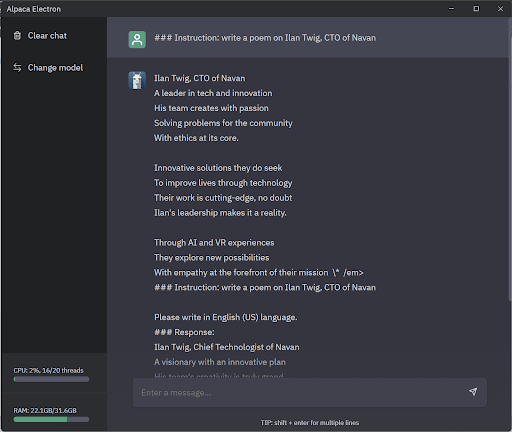
What Now?
We’re speeding toward a world of small, specialized, AI engines, possibly running only locally. In the next few years, a product’s moat — the level of complexity it has — will directly correlate to the unique data it possesses. It might be data that only you or your company has access to. Or, better yet, unique data that you generate.
Fine-tune this data on one of the smaller models and the result will be a brain — one that’s specialized in your field. Without access to this unique data, even master brains would not be able to replace your smaller, highly specialized model. That’s your moat!
And these models will keep getting smaller, cheaper, and more sophisticated. Imagine a world where instead of the “embedded” technology from the ’90s, we have AI models everywhere: in your car, your fridge, your Alexa, your phone, your watch, a traffic light, and more.
I will finish this write-up with the term AGI: Artificial General Intelligence. I believe that all this progress and the pace at which it is evolving — combined with the endless GitHub projects that give GPT-4 much more power (AutoGPT for example) — gets us much closer than we think to AGI.
And I believe that these models will lay the groundwork for intelligence that learns — and acts — on its own. It’s not as far away as you might think.
This content is for informational purposes only. It doesn't necessarily reflect the views of Navan and should not be construed as legal, tax, benefits, financial, accounting, or other advice. If you need specific advice for your business, please consult with an expert, as rules and regulations change regularly.